实时语音转文字 (STT) 与模型选择
无界音流的核心功能是基于本地模型的实时语音转文字(STT)。它能够精准、快速地将您的语音转化为文字,并支持多种输出方式。
实时 STT 功能介绍
无界音流支持 SenseVoice ONNX 与 FunASR 两条本地实时 STT 路径。两者都支持临时流式结果与句级最终结果,您说话时即可持续看到文字上屏。
当前 STT 路径: 麦克风实时识别支持 SenseVoice ONNX 与 FunASR;新增的 native-stt 主要用于上传音频文件后的离线转写,支持 Whisper / SenseVoice 两种原生后端。
输出方式
在设置中,您可以选择不同的输出方式:
- 跟随光标注入(推荐):边说边写,识别结果直接输入到您当前光标所在的位置。开启后,请先用鼠标点到你想输入的地方(如 Word、网页输入框),再开始说话。
- 实时输出:在应用界面内实时显示识别结果。
- 最终自动回车:在一段话讲完后,自动输出最终结果并换行。
如何开启实时 STT
确认配置
确保您已经正确配置了模型目录(见下文)。
开始录音
方式一:点击主界面上的 “开始录音” 按钮。
方式二:在任何界面下,按下键盘上的 右侧 Alt 键 (RightAlt)。
结束录音
开始说话吧!您会看到识别的文字实时显示出来。再次按下快捷键或点击停止按钮即可结束录音。
选择与配置不同模型
为了让语音识别功能正常工作,您需要进行简单的模型配置:
选择后端并配置模型目录
- 打开应用主界面,进入 设置 (Settings)。
- 在 STT 后端中选择要使用的实时后端(ONNX 或 FunASR)。
- 在 模型目录 中选择对应后端的模型文件夹路径。
推荐模型下载(ModelScope)
无界音流默认使用 SenseVoice 本地模型(ONNX)。推荐使用 ModelScope 下载(参考 ModelScope 文档;小白安装指南见 附录 A):
modelscope download --model iic/SenseVoiceSmall --local_dir ./SenseVoiceSmall下载完成后,将设置里的 模型目录 指向下载目录(例如 ./SenseVoiceSmall 或 Windows 绝对路径)。
如果您选择 FunASR 后端,请下载 FunASR-Nano 模型,并将 模型目录 指向该目录:
modelscope download --model FunAudioLLM/Fun-ASR-Nano-2512 --local_dir ./Fun-ASR-Nano-2512注意: ONNX 后端请确保目录中包含 model.onnx 与 tokens.json;FunASR 后端请确保目录为完整的 Fun-ASR-Nano-2512 模型目录(例如包含 model.pt、config.yaml、tokenizer 相关文件)。
说话人分离(Speaker Diarization)额外模型
如果您希望实时识别时自动区分不同说话人,除了 STT 主模型外,还需要额外配置一组 sherpa-onnx 的说话人分离模型。它们与 SenseVoice / FunASR 是并行关系,不是二选一。
- segmentation.onnx:负责把整段音频切分成不同说话人的时间片段。
- embedding.onnx:负责提取每个说话人的声纹向量,用于聚类与区分
Speaker_1 / Speaker_2 / Speaker_3。
推荐把文件放到同一个目录,例如:
F:\Projects\03.AIWhiteBoard\ai-whiteboard-next\voice\speaker-diarization\
segmentation.onnx
embedding.onnx然后在应用设置中配置:
- 说话人分段模型:选择
segmentation.onnx或其所在目录 - 声纹嵌入模型:选择
embedding.onnx或其所在目录
推荐下载来源:
- 分段模型:
sherpa-onnx-pyannote-segmentation-3-0 - 嵌入模型:
3dspeaker_speech_eres2net_base_sv_zh-cn_3dspeaker_16k.onnx - 官方说明:sherpa-onnx speaker diarization models
补充说明: SenseVoiceSmall 用于实时识别、情感/语言/事件标签;Fun-ASR-Nano-2512 用于 FunASR 实时识别。它们都不能直接替代 segmentation.onnx 与 embedding.onnx。
高级 STT 设置
- 发送帧间隔(毫秒):决定语音识别的实时性。建议设置为
20ms(接近实时)。数值越小,文字上屏越快,但会增加电脑性能消耗。 - 识别语言:强制指定识别的语言(如中文、英文、日文等)。推荐选择 自动 (auto),让 AI 自动判断。
- TextNorm:文本标准化处理。推荐保持 auto(默认)。
native-stt 离线文件转写
升级后的 native-stt 提供了一条与实时麦克风 STT 并行的离线转写路径。它适合较长录音、历史音频、会议回放和本地批量转写场景。
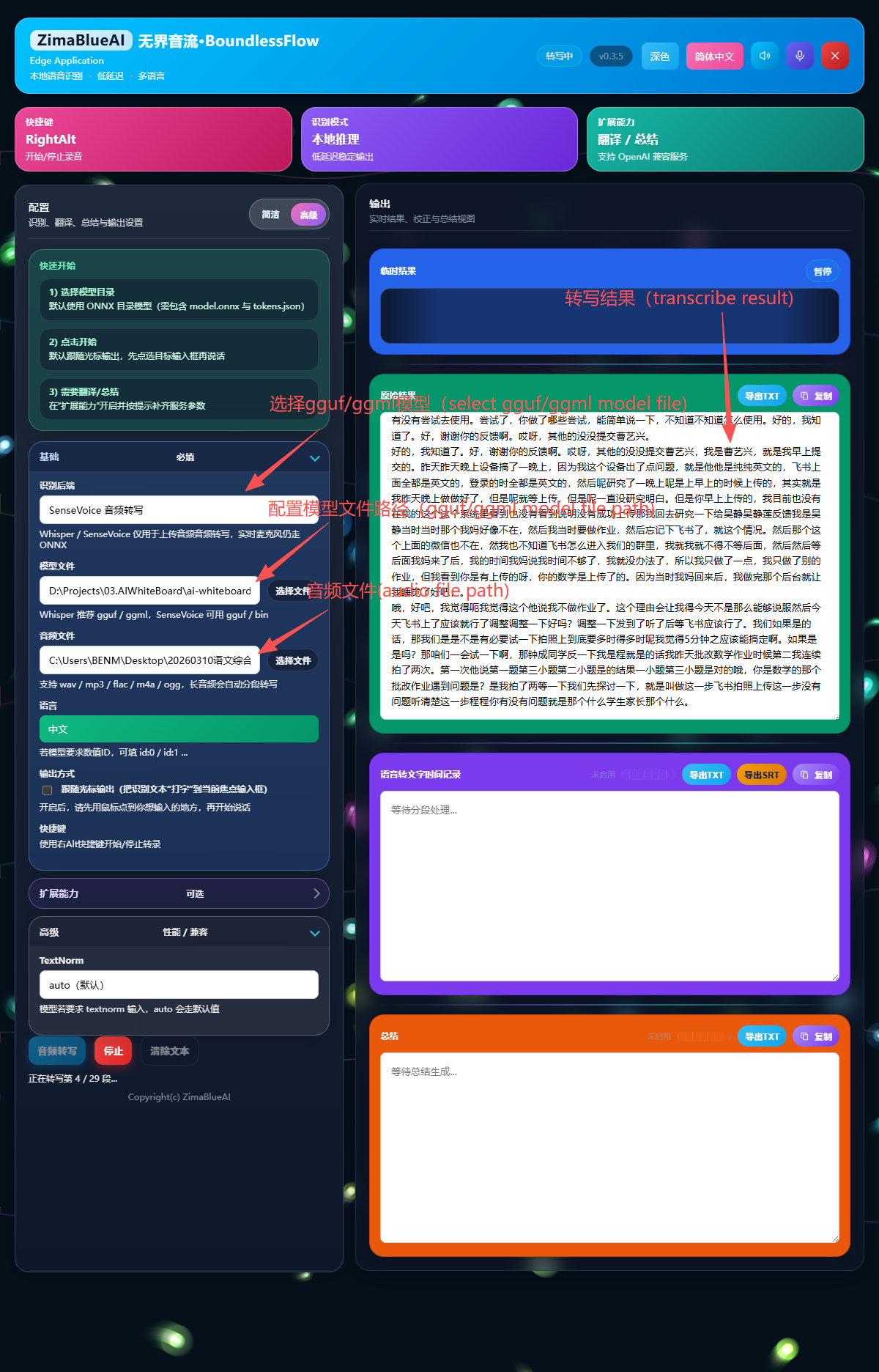
适用场景与特点
- 仅用于音频文件转写:该路径用于上传/本地音频文件,不替代实时麦克风识别;实时录音请使用 ONNX 或 FunASR 实时后端。
- 支持原生后端:可切换
Whisper或SenseVoice,按模型类型选择最适合的转写引擎。 - 长音频更稳妥:应用会按片段处理较长文件,并把结果持续追加到“原始结果”区域。
- 可中途中止:转写过程中可以点击停止按钮终止当前任务。
- 自动优先 CUDA:系统具备可用 CUDA 环境时,native-stt 会优先尝试 GPU 加速。
如何配置 native-stt
- 在主界面的 STT 面板中,将后端切换为 Whisper 或 SenseVoice。
- 选择对应的 模型文件 或模型路径。
- 再选择需要转写的 音频文件。
- 点击 转写文件,结果会逐步写入“原始结果”区域。
模型与格式说明
- Whisper:适合使用
.bin、.ggml、.gguf模型文件。 - SenseVoice:适合使用
.bin或.gguf模型文件。 - 语言建议:大多数情况下保持
auto即可;如需提高稳定性,可手动指定语言。
注意: native-stt 当前定位为离线文件转写能力,不用于实时麦克风字幕。如果您希望边说边显示,请使用 ONNX 或 FunASR 的实时 STT 路径。
Copyright(c) ZimaBlueAI
齐码蓝智能(大理市 )有限责任公司